如何讓 LLM 在不同session 之間不間斷地執行任務?從 Long-running Agent 框架看Harness Engineering
分享我做的 Flywheel — 一個 Long-running Agent 的 agentic development workflow scaffolding,從「Harness Engineering」的層次來拆解看看。
先講什麼是 Harness?
之前分享 Claude Code source code 分析時有提到:
- Harness 是設計一套作業系統
- Agent 就是 Process
- LLM 是 CPU
- Context Window 是 RAM
Harness 就是你幫 agent 設計的軌道:什麼時候該規劃、什麼時候該實作、什麼時候該停下來 review、做完怎麼交班(設計他的能力邊界、工作指南)。
如果很 naive 的使用 Coding Agent 的話,其實真的蠻容易遇到這種問題:Coding Agent 嘗試去 build 一個 feature,然後直接把整個 feature 一次寫完,寫完了也不一定正確。此外 context window 燒完之後,下一個 session 要怎麼繼續接手?可能只拿到一半的東西,甚至完全不知道怎麼往下接手。
Harness Engineering 其中一個工作就是在解這件事 — 幫 agent 設計「怎麼正確地工作」的結構。
在做 Flywheel 的過程中,這個 harness 具體落地成幾個工程概念
𝟏. Planning — 整個流程最關鍵的環節
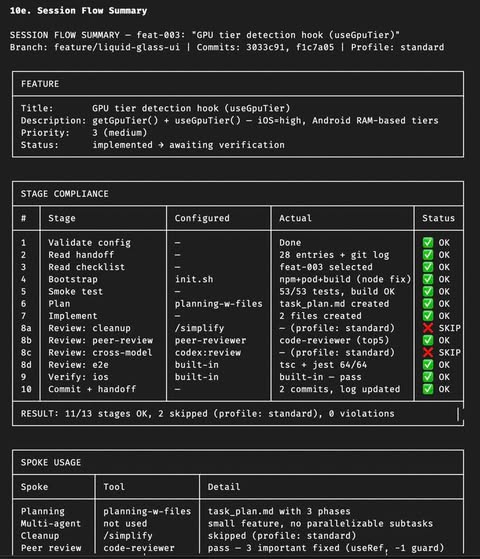
在研究和實作的過程中,最大的體會是 planning 比想像中重要太多。中間只要設計判斷出了錯誤,整個 session 就要重新來過。前期的 spec 如果拆得好,對應的 feature list 就比較容易做對,agent 每一棒的執行品質也會更穩定。
通常初期的 Spec,我會直接開一個獨立的 Code Agent 獨立 Session 從頭跑一次,甚至會找多個 Model 確認一下。因為這個初期 Spec 是在 Explore 整個開發的地圖,只要少了幾個關鍵字,或是改變了幾個要前進的目標,其實 Planning 出來的東西會變得非常不一樣,甚至會從可用變成不可用。
我自己也用 AutoResearch 改了一個適合我的 omni-research,燒 Token 來提煉出比較好的 Planning Context。
𝟐. Multi-agent — 做的人跟評的人必須分開
跟上最近的潮流,Codex 的 Claude Code skill,那我們就可以讓實作的人跟 review 的人是分開的。Cross Model Review 的好處是巨大的。
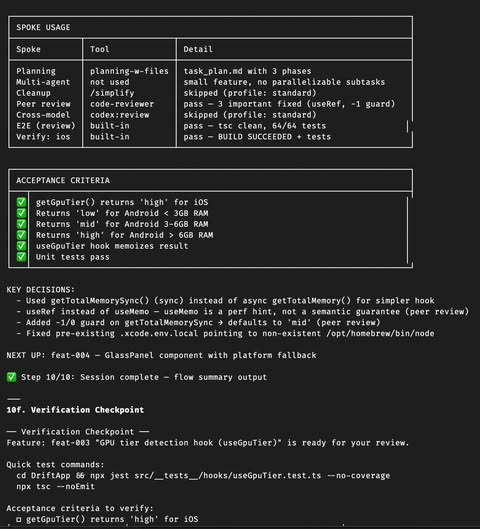
Flywheel 的 review 是獨立的 multi-agent pipeline,不是讓同一個 agent 自己評自己:
- Cleanup:用 superpowers
/simplify做第一輪清理 - Peer review:開一個新的 agent 來看 bugs、security、logic errors
- Cross-model:用
codex:review讓 OpenAI 的 model 來 review Claude 寫的 code — 兩個不同的 AI 看同一份 code,重疊的 findings 就是高信心問題 - E2E:Playwright 真瀏覽器或 CLI 測試
𝟑. E2E Verification — agent 最容易偷懶的環節
沒有明確要求的話,agent 做完 code 跑個 unit test 就會標記 done。但 unit test pass 不代表 feature 真的 work。加上瀏覽器測試與 simulator 測試之後,agent 能抓到很多光看 code 看不出來的 bug。
這是 harness 滿關鍵的一部分:在流程裡「卡」一個 verification 的關卡,agent 可以判斷是否通過 Acceptance Criteria。
不過世界沒有這麼美好,即使卡這步驟,我常常不覺得他真的有把修正都做對,因為常常改壞其他東西呀(偉哉文字接龍🥵)。
𝟒. Context 落地到 Filesystem — 跨 session 的記憶不能只靠 context window
每個 session 結束的時候,所有狀態都寫在磁碟上 — feature list(JSON)、交班日誌(JSONL)、git log。下一個 session 進來讀這些檔案就能直接動工。
每個 session 都是 disposable 的,開、關、crash 都沒差。只要交班日誌在,下一個 session 就能繼續跑。
Harness 會隨模型能力一起演化
Anthropic 曾在研究裡提了一個我覺得很重要的觀點:harness 裡的每一個 component,都編碼了一個「對模型能力的假設」。
模型變強的時候,這些假設要重新 stress test。有些 component 不再需要(比如 Opus 4.5 改善了 context anxiety 之後,context reset 就不一定要做了),有些則可以做到以前做不到的事。
所以 harness 不是做一次就定了,它會隨著模型能力一起演化,甚至如何選用適當模型在哪個環節的判斷以及最後的最後…我們的工程能力也必須持續演化 😳
整個流程從一份 spec 開始,不需要額外設定 repo 環境。只要 repo 本身的 CLAUDE.md 和專案結構寫得清楚,agent 自然會找到對應的工具來實作。
與 agent 的協作比什麼都重要 — 尤其是前期的 spec。Spec 寫得好,flywheel 就會自己轉起來。
而且我覺得最好玩的部分是,可以從這個 Long-running 的骨架再擴充出自己專屬的子元件 — Research Agent、KB Retrieval、Memory Management、Testing Agent 等等☝️
每個人在意的東西不一樣,所以每個人的 harness 也會長不同的樣子。分享一下我自己的版本🫶🫶🫶