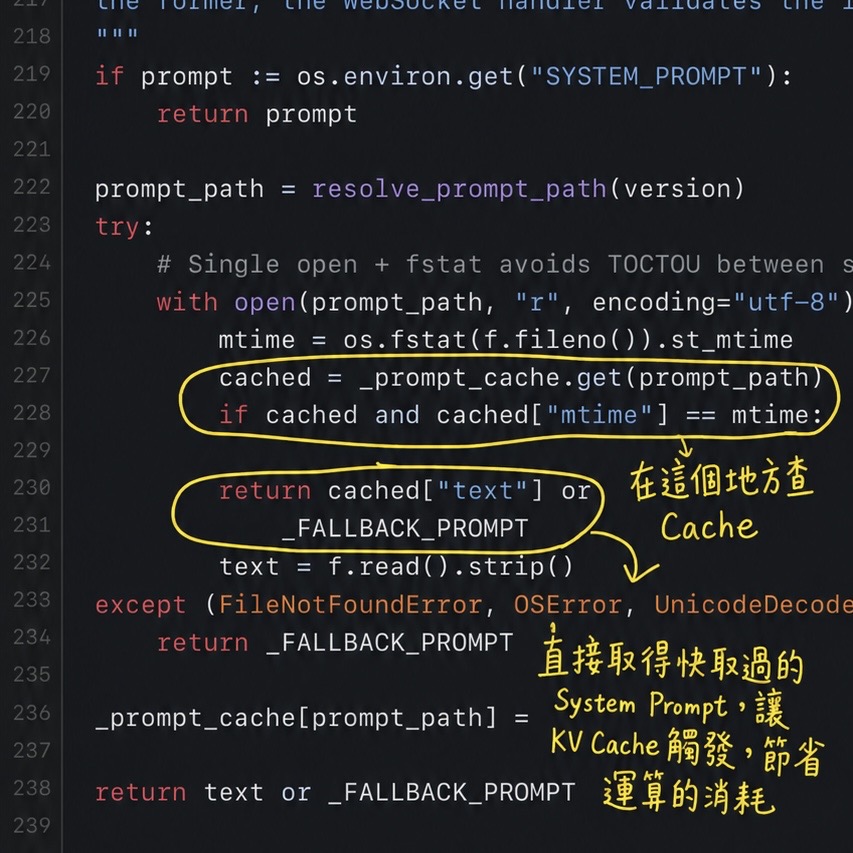
研究 agent 系統研究到一半,我發現自己連「為什麼會有 prompt cache」都講不清楚 — 追到底才發現,就真的只是 "cache" 那個 "cache"😂,只是這次給 GPU 用。
最近在搞 local autonomous agent 的東西,一直看到 prompt caching 可以省錢,但我發現我只會「用」,講不出「為什麼」。於是我就乾脆從頭問 AI 找資料:prompt cache 這個概念,到底是怎麼長出來的。
一、為什麼會有 cache 這個東西
先講 Transformer 在幹嘛。它每處理一個 token,都要跟前面所有 token 算 attention,這個過程會吐出每一層的 Key 跟 Value 向量(業界都叫 KV)。
重點來了 — 同一段 token,算出來的 KV 是固定的。不管你後面接什麼,前面那段的 KV 永遠長一樣。
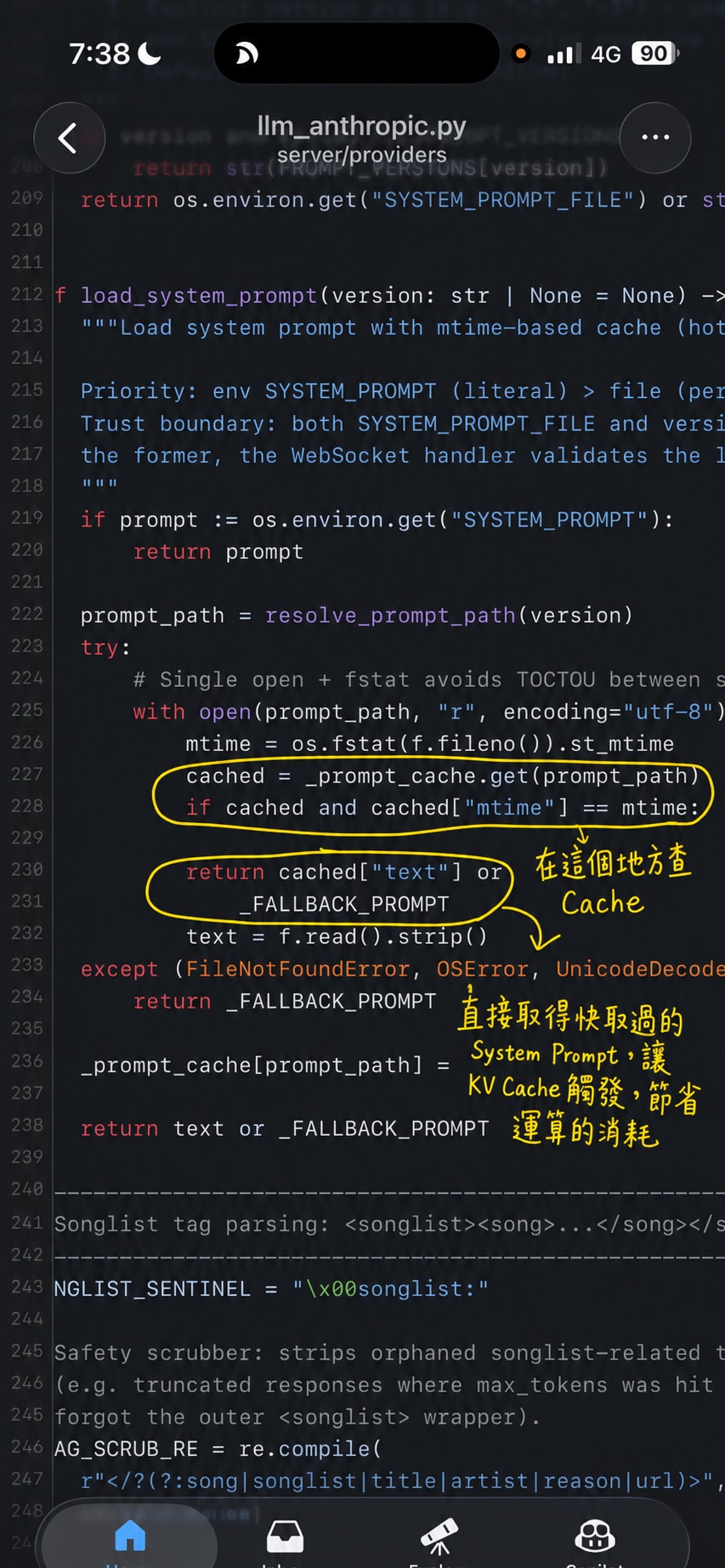
那這就很讚了嘛,既然結果固定,幹嘛每次都重算。算過一次存起來,下次遇到一樣的開頭直接載入,不就好了。
啪,這就是 prompt cache。
說穿了就是 memoization — 把算過的結果記住,別再算第二次。大學資料結構就教過,只是這次的「結果」是一坨 GPU 算出來的矩陣而已。
二、為什麼只能 cache「開頭」
這邊是我覺得最有意思的地方。你可能會想:那我中間某一段重複的,能不能也 cache 起來重用?
不行(至少現在的主流實作不行)。
因為 attention 是 causal 的 — 每個 token 的 KV,是由「它前面所有 token」決定的:
Token C 的 KV = f(A, B, C)
所以只要改了開頭的 A,即使 C 一個字都沒動,C 的 KV 還是會變。
這就導致一個很硬的限制:cache 只能從開頭逐 token 比對,中間斷一個就全毀。
我猜啦,這也是為什麼所有 prompt 設計的最佳實踐都長一樣 —
- 把不會變的東西(system prompt、tool 定義、persona)往前擺
- 把每次都在變的東西(使用者輸入)往後丟
天然地順著 causal attention 的數學特性設計。
三、多輪對話其實一直在偷吃 cache
這個想通之後就簡單了,我們每一輪對話,送出去的其實是「整串」:
第 1 輪:[system][msg1]
第 2 輪:[system][msg1][回覆1][msg2]
第 3 輪:[system][msg1][回覆1][msg2][回覆2][msg3]
每一輪你只是在尾巴追加新東西,前面完全沒變。所以前面那段的 KV cache 還熱著,GPU 直接載入,只算最後新增的那一小段。
對話越長,cache 命中的比例越高 — 因為「舊的」越來越長,「新的」永遠只有最後一輪。
cache 每一輪都在發生 🤭
四、然後就講到錢了
Anthropic 的 token 計費大概分三種(確切倍數會因 model 跟 cache 時長不同,這邊抓個量級):
- 正常 input token:1x
- cache write(第一次寫進去):大約 1.25x,稍微貴一點
- cache read(命中快取):大約 0.1x,便宜超多
假設我 fork 出 5 個 agent,它們共用同一段 100K 的 context prefix,只有最後的任務指令不同:
沒 cache: 5 × 100K × 1x = 500K 單位
有 cache: 100K × 1.25 (第一個寫入)
+ 4 × 100K × 0.1 (後面四個用讀的)
= 165K 單位
省下大概 67%。
越多 agent 且可能共用資料的場景,這個差距是會直接反映在帳單上的。
五、最後一個我沒想到的點
cache 是跟「session」綁定的嗎?還是跟「使用者」綁定的嗎?
都不是。
它純粹看 token 序列的前綴,不管你是誰、哪個對話、甚至哪個 API key。
使用者 A:[system prompt X][...] → 寫入 cache
使用者 B:[system prompt X][...] → 直接命中,根本不認識 A
想像 GPU 上有一個共用的 KV cache pool,誰的 prefix 撞上了就能用。
(但它有 TTL,大約 5 分鐘 / 1 小時沒人碰就被清掉,所以是「熱快取」的概念,不是永久存著)
所以如果設計一個 app,用戶共享同一份 system prompt 跟 persona,那份的 KV 可能早就在 GPU 記憶體裡了,後面的人全部用讀的。
繞了一大圈,結論
prompt cache 聽起來很 AI,但它骨子裡就是 memoization + 記憶體階層 — 把「算過的別再算」這件簡單的設計,套到 attention 的 KV 上。
省錢。
加速。
很多 AI infra 的東西其實都這樣,名字很潮,拆開來都是 CS 基礎在撐。
愈把這些新東西翻譯回 OS / 計算機結構的老語言,就愈不嚇人 🧘